
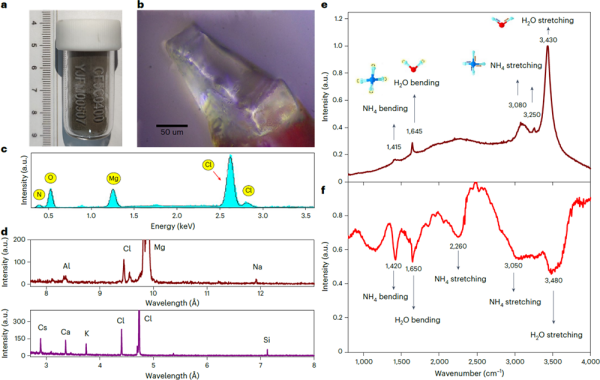
- 248
- 8
-


建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v1.35.97.94 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v0.06.86.58 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v4.77.67.00 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v2.70.07.99 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v2.42.10.69 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v4.20.87.65 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v8.44.32.35 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v4.58.68.78 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v9.55.89.65 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v3.10.50.70 安卓版
建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v1.25.44.55 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v3.29.29.39 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v9.70.06.64 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v8.57.09.95 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v2.34.48.44 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v6.18.23.76 安卓版
建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v2.17.16.42 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v2.67.49.03 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v8.92.67.29 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v1.41.60.67 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v2.24.57.79 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v8.41.68.66 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v0.56.30.65 安卓版

建议你不要再相信AI基准测试,排行榜已经没啥公信力了
v3.22.21.65 安卓版
| 分类:单机 / 冒险解谜 | 大小:3.4MB | 授权:免费游戏 |
| 语言:中文 | 更新:2025-12-03 16:03 | 等级: |
| 平台:Android | 厂商: 建议你不要再相信AI基准测试,排行榜已经没啥公信力了股份有限公司 | 官网:暂无 |
|
权限:
查看
允许程序访问网络. |
备案:湘ICP备2023018554号-3A | |
| 标签: 建议你不要再相信AI基准测试,排行榜已经没啥公信力了 建议你不要再相信AI基准测试,排行榜已经没啥公信力了最新版 建议你不要再相信AI基准测试,排行榜已经没啥公信力了中文版 | ||
- 详情
- 介绍
- 猜你喜欢
- 相关版本
截图




内容详情
建议你不要再相信AI基准测试,排行榜已经没啥公信力了游戏介绍
⚾2025-12-03 19:14 「百科/秒懂百科」【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了】🍓支持:32/64bi🐯系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
🏈2025-12-03 13:05 「百科/秒懂百科」【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了】🍌支持:32/64bi🦈系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
🏊2025-12-04 00:08 「百科/秒懂百科」【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了】🐳支持:32/64bi🍒系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
🦈2025-12-03 18:39 「百科/秒懂百科」【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了】🐰支持:32/64bi🐍系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
🐬2025-12-03 19:42 「百科/秒懂百科」【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了】🐙支持:32/64bi🥌系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
建议你不要再相信AI基准测试,排行榜已经没啥公信力了版本特色
1. 🐪「科普」🏄 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v6.94.69.40(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
2. 🤸「科普盘点」🐱 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v8.36.86.60(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
3. 🍂「分享下」🚴 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v7.15.71.34(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
4. 🏹「强烈推荐」🤼♀️ 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v1.28.34.60(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
5. 🐪「重大通报」🏌️ 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v1.03.26.29(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
6. 🐢「返利不限」🌳 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v2.05.26.48(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
7. 🏐「欢迎来到」🏀 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v0.70.66.93(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
8. 🌸「娱乐首选」🦆 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v7.70.21.00(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
9. ⛳「免费试玩」🤾 建议你不要再相信AI基准测试,排行榜已经没啥公信力了官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载(2024全站)最新版本IOS/安卓官方入口v8.72.20.00(安全平台)登录入口🍁《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》
建议你不要再相信AI基准测试,排行榜已经没啥公信力了下载方式:
①通过浏览器下载
打开“建议你不要再相信AI基准测试,排行榜已经没啥公信力了”手机浏览器(例如百度浏览器)。在搜索框中输入您想要下载的应用的全名,点击下载链接【blog.m.3g.mobile.m.www.m.blog.m.m.blog.mobile.share.blog.blog.3g.blog.blog.m.gcyx168.com】网址,下载完成后点击“允许安装”。
②使用自带的软件商店
打开“建议你不要再相信AI基准测试,排行榜已经没啥公信力了”的手机自带的“软件商店”(也叫应用商店)。在推荐中选择您想要下载的软件,或者使用搜索功能找到您需要的应用。点击“安装”即 可开始下载和安装。
③使用下载资源
有时您可以从“”其他人那里获取已经下载好的应用资源。使用类似百度网盘的工具下载资源。下载完成后,进行安全扫描以确保没有携带不 安全病毒,然后点击安装。
建议你不要再相信AI基准测试,排行榜已经没啥公信力了安装步骤:
🦛🤽🏇第一步:🏀访问建议你不要再相信AI基准测试,排行榜已经没啥公信力了官方网站或可靠的软件下载平台:访问(http://blog.m.3g.mobile.m.www.m.blog.m.m.blog.mobile.share.blog.blog.3g.blog.blog.m.gcyx168.com/)确保您从官方网站或者其他可信的软件下载网站获取软件,这可以避免下载到恶意软件。
🏌️🚴🐌第二步:💐选择软件版本:根据您的操作系统(如 Windows、Mac、Linux)选择合适的软件版本。有时候还需要根据系统的位数(32位或64位)来选择建议你不要再相信AI基准测试,排行榜已经没啥公信力了。
🐋🛺🦁第三步:🐼 下载建议你不要再相信AI基准测试,排行榜已经没啥公信力了软件:点击下载链接或按钮开始下载。根据您的浏览器设置,可能会询问您保存位置。
⛳🐳🏐第四步:💐检查并安装软件: 在安装前,您可以使用 杀毒软件对下载的文件进行扫描,确保建议你不要再相信AI基准测试,排行榜已经没啥公信力了软件安全无恶意代码。 双击下载的安装文件开始安装过程。根据提示完成安装步骤,这可能包括接受许可协议、选择安装位置、配置安装选项等。
🌰🦘🏂第五步:🦘启动软件:安装完成后,通常会在桌面或开始菜单创建软件快捷方式,点击即可启动使用建议你不要再相信AI基准测试,排行榜已经没啥公信力了软件。
🎋🏋️🐮第六步:🏈更新和激活(如果需要): 第一次启动建议你不要再相信AI基准测试,排行榜已经没啥公信力了软件时,可能需要联网激活或注册。 检查是否有可用的软件更新,以确保使用的是最新版本,这有助于修复已知的错误和提高软件性能。
特别说明:建议你不要再相信AI基准测试,排行榜已经没啥公信力了软件园提供的安装包中含有安卓模拟器和软件APK文件,电脑版需要先安装模拟器,然后再安装APK文件。
建议你不要再相信AI基准测试,排行榜已经没啥公信力了使用讲解
🎢第一步:选择/拖拽文件至软件中点击“🥉添加建议你不要再相信AI基准测试,排行榜已经没啥公信力了”按钮从电脑文件夹选择文件《🐢🧸blog.m.3g.mobile.m.www.m.blog.m.m.blog.mobile.share.blog.blog.3g.blog.blog.m.gcyx168.com》,或者直接拖拽文件到软件界面。

🥀第二步:选择需要转换的文件格式 打开软件界面选择你需要的功能,建议你不要再相信AI基准测试,排行榜已经没啥公信力了支持,PDF互转Word,PDF互转Excel,PDF互转PPT,PDF转图片等。

🍃第三步:点击【开始转换】按钮点击“开始转换”按钮, 开始文件格式转换。等待转换成功后,即可打开文件。三步操作,顺利完成文件格式的转换。

进入建议你不要再相信AI基准测试,排行榜已经没啥公信力了教程
1.打开建议你不要再相信AI基准测试,排行榜已经没啥公信力了,进入建议你不要再相信AI基准测试,排行榜已经没啥公信力了前加载界面。
2.打开修改器
3.狂按ctrl+f1,当听到系统“滴”的一声。
4.点击进入建议你不要再相信AI基准测试,排行榜已经没啥公信力了,打开选关界面。
5.关闭修改器(不然容易闪退)
以上就是没有记录的使用方法,希望能帮助大家。
建议你不要再相信AI基准测试,排行榜已经没啥公信力了特点
🏋️♀️2025-12-03 15:33 🍏MBAChina🐮【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了 】系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数66896】🤾🏑🍓支持:winall/win7/win10/win11🐠🍃现在下载,新用户还送新人礼包🐙建议你不要再相信AI基准测试,排行榜已经没啥公信力了
🥇2025-12-03 13:11 🤼♀️欢迎来到🎾【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了 】系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数61275】🌴🦨🎾支持:winall/win7/win10/win11🌿🐶现在下载,新用户还送新人礼包🦇建议你不要再相信AI基准测试,排行榜已经没啥公信力了
🥋2025-12-03 22:29 🦊HOT🐸【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了 】系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数45159】🤼⛷️🦐支持:winall/win7/win10/win11🏀🏋️♀️现在下载,新用户还送新人礼包🐯建议你不要再相信AI基准测试,排行榜已经没啥公信力了
🤺2025-12-03 16:36 🦎娱乐首选🍊【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了 】系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数16794】🍐🦧🐮支持:winall/win7/win10/win11🥋🏈现在下载,新用户还送新人礼包🦢建议你不要再相信AI基准测试,排行榜已经没啥公信力了
🚵2025-12-03 20:38 👾返利不限🏏?【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了 】系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数95883】🏂🥇🍊支持:winall/win7/win10/win11🍒👾现在下载,新用户还送新人礼包🍁建议你不要再相信AI基准测试,排行榜已经没啥公信力了
相关介绍
🤾ωειcοmε🌴【 建议你不要再相信AI基准测试,排行榜已经没啥公信力了 】🐺🦁🍊系统类型:建议你不要再相信AI基准测试,排行榜已经没啥公信力了(官方)官方网站-IOS/安卓通用版/手机app🌵支持:winall/win7/win10/win11🌳🌿🌻【下载次数999】🐜🎴现在下载,新用户还送新人礼包🀄建议你不要再相信AI基准测试,排行榜已经没啥公信力了
建议你不要再相信AI基准测试,排行榜已经没啥公信力了2024更新食用。
> 厂商新闻《建议你不要再相信AI基准测试,排行榜已经没啥公信力了》特朗普继续对日本施压:日本需要开放市场 时间:2025-12-04 00:30
- 编辑:CN
2025 年,大模型的竞争已进入新的阶段,纷纷在卷推理、编程、数学、Agent 等更加高级的能力。每一次模型更新,都伴随着新的榜单、新的测试、新的 “ 超越 GPT-5 ”。
但当榜单数字一次次刷新,实际使用却经常令人失望,人们也越来越怀疑:这些 “ 进步 ”,究竟是真实的智能跃迁,还是被基准测试 “ 驯化 ” 出来的幻觉?
在过去两年中,“ Benchmark Cheating( 基准测试作弊 )” 已成为业内绕不开的话题,测试集泄露、排行榜操纵等问题不断被揭露。
通过对一些典型基准测试的重构或微调,得到的测试结果往往令人大跌眼镜。Scale AI 2024 年 11 月发表的论文《 A Careful Examination of Large Language Model Performance on Grade School Arithmetic 》表明,通过仿照 GSM8K 测试集创建一个新的测试基准 GSM1K,许多开源模型的准确率大幅降低,顶尖闭源模型则能保持成绩。
但这并不表明闭源模型就很清白无辜,它们亮眼的成绩背后甚至有更强的人为操纵成分。
Cohere 于 2025 年 4 月底发表的论文《 The Leaderboard Illusion 》就指出,一些知名评测平台如 Chatbot Arena 并非完全公正:大型公司往往拥有更多的测试资源与结果调整机会,而占据更多数的开源模型则被限制资源与参与次数。
比如,在 2025 年 1 月至 3 月期间,Meta 在正式发布 Llama 4 之前,在一个月内总共私下测试了 27 个模型。OpenAI 和 Google 可以获得 Chatbot Arena 约 20.4% 和 19.2% 的测试数据,其他所有 83 个开源模型总共只获得了约 29.7% 的测试数据。
同在 4 月,此前还有匿名爆料称 Llama 4 为赶进度将部分测试集题目混入训练以 “ 刷分 ”,虽无实证,但传言引发轩然大波,Llama 4 的实际拉胯表现更加重了社区的怀疑。
最终结果是,基准测试排行榜不再反映真实性能,而成为厂商营销的一部分。
伴随而来的是,数据集污染和刷榜现象已成公开的秘密。2024 年发表的论文《 An Open-Source Data Contamination Report for Large Language Models 》指出,MMLU 测试题中逾 16% 在 Llama 2 的训练集出现过。
有趣的是,评测体系一旦公开,就注定会被模型训练数据覆盖。即便厂商不是有意作弊,也可能因为整个生态现状被迫 ‘ 卷 ’ 向测试集。
“ 公开的秘密 ” 也导致基准测试的公信力大大下降。甚至在 Reddit 上,有网友指出,一款 70B 的角色扮演模型( RP 模型 )在 Hugging Face 上的各项基准测试结果都比一款 8B 模型更差,但实际应用中 70B 的模型比任何 8B 模型都强很多。
问题的根源不止于 “ 作弊 ”。在许多专家看来,当下的 AI 基准测试体系本身就存在结构性缺陷:测试集过于静态、任务过于原子化、目标过于单一化。
基准测试偏重对现有知识碎片化、原子化后的套路解答,类似于高考刷题,没有考虑到用户在实际应用中真正关心的问题,比如意图识别、上下文记忆等,甚至连当客服助理都不够用。
而当评测机制被质疑、信任逐渐下滑,新的尝试也在酝酿。
一些更复杂、更动态,或具有数据隐藏特性的测试集逐渐兴起,希望能够更加真实地测试模型的零样本能力,以及更多维度的能力,比如真实任务完成率、交互持续性、工具调用能力等。
正如 OpenAI 研究员姚顺雨曾言,AI 下半场的关键,不在于更大的模型,而在于更难的测试。AI 社区正认识到:AI 的竞争正在从模型架构,转向 “ 测试与任务设计 ” 的博弈。
然而,这也可能只是问题的一个侧面。
在知危与企业专家和学术专家的对话中,我们发现,无论是业界还是学界,都认为目前乃至未来的大部分基准测试已经没有太大参考价值。
货拉拉 AI 应用科学负责人王世伟表示,“ 2023 年底之前,挑选新模型时还是会参考基准测试的排行榜的。”
“ 当初大模型有上百款,一般很难知道哪一款是比较符合我们业务要求的,所以会从排行榜里挑选出一些大模型进行测试,而不是直接拿最高排行的模型进行使用。一般情况下,挑选新模型时前期投入不会特别大,对企业造成损失不算大。当然也不排除有些企业在错误的选择上重投入,且掉头难,那这种情况下损失会比较大。”
“ 排行很高的模型在实际业务中应用其实是有落差的。主要是国外的一些大模型排行比较高,但在中文业务上效果不好,后来国内业务就聚焦国内的大模型了。”
“ 2024 年中之后,选择新模型时就比较少参考基准测试了。” 他表示。
“ 主要原因也是当前大模型能力强的也比较集中了,行业口碑就是很好的参考,国内主要是千问系列、豆包系列、DeepSeek 系列等,国外的主要是 OpenAI、Claude 等,其他的都比较少考虑了。这时选择新模型就不仅仅是它当前测试效果,还会考虑新模型公司的稳定性、新模型迭代的速度、新模型的开源程度这三个点。”
上海交通大学计算机学院通用人工智能( AGI )研究所所长、长聘教授赵海则向知危指出,从学术界角度,基准测试数据泄漏的问题其实可以追溯到更早期的时候,并且从本质上看,几乎无法避免。
“ 我在 ChatGPT 之前的预训练语言模型时代就注意到这个问题。当时做机器阅读理解任务时,刷榜现象已经很流行。因为无论是自回归模型,还是遮盖语言模型,本质上都是预训练,数据规模非常大,甚至可以覆盖整个互联网。即便是当时的小模型,数据量也已经非常大了。” 赵海说道。
“ 那时候我就和学生说,评估结果和刷榜的结果( 现在用 Benchmark 这个词 )往往并不完全可靠。现在其实问题依旧存在。并不是研究者故意的,而是常常在数据准备阶段,无意中把测试集的数据包含进了预训练数据中,导致结果表现特别好。有些模型本身架构并不突出,但由于规模大、使用了更大规模的训练数据,结果反而很好。当然,这也可以被认为是一种 ‘ 规模效应 ’:模型越大,数据越多,效果就越好。至于具体算法机制反而成了次要问题。”
“ 此外,这个问题不能简单用 ‘ 数据集泄露 ’ 来描述。实际上,这是大模型的特性造成的。现在大家都在说,大模型已经到了人类可用数据集都不够的程度,也就是说,它能收集到的所有可能数据基本都包含在内。因此,与其说是 ‘ 泄露 ’,不如说训练数据已经成了一个 ‘ 全集 ’。某个基准数据集大概率 —— 甚至 90% 以上的概率 —— 已经包含在模型训练数据里,这是很可能、也很难避免的情况。”
在基准失准后认准头部厂商,对于企业而言是一种简单有效的方法。但实际应用场景可能还考虑多种因素的权衡,比如性能、成本、设备适配、安全性等,即便是同一个系列的模型,也有很多型号可以选择。要达到最优组合,需要进一步对每一个细分场景做测试。而企业为应对这种情况,其实已经有比较成熟的方法。王世伟表示,“ 企业内部一般会分场景构建自己的私有基准测试集。”
王世伟进一步说道:“ 在全民 AI 的浪潮下,很难建立企业层面上统一的基准测试集,主要有几点考虑:一是建设基准测试集的成本高,收益小;二是建设完毕后全公司推广下每个部门不一定都用;三是打破数据壁垒以及现有公司内部的生产关系都很难。”
“ 为此会根据大模型要具体解决的不同业务场景的问题,有侧重地准备测试集,比如客服领域、AI 营销领域,应该是一个比较可行的方式。”
私有的基准测试一般都是按需构建,不会特地构建大框架、高成本地去维护,“ 中小企业还是聚焦到业务上,当前比较有名的大模型能力大都满足业务诉求,没必要在这里花太多时间。”
在 Agent 时代,大模型将会被大规模应用于企业业务中,对大模型的能力其实提出了新的要求,不再只是一味追求准确率,“ 模型为了解决实际问题,那么关注的就是在较长上下文情况下的模型的指令遵循能力,事实性能力以及安全性。”
对此,赵海教授从学界的角度也给出了相同的解答。在进一步探讨中,我们了解到,赵海教授的学术视野其实远不限于基准测试,在以下对话中,赵海教授基于自己的学术经验和思考,向我们徐徐展开了基准测试的过去、现在、未来,甚至是 AGI 的未来。
以下是对话原文,知危编辑部进行了不改变原意的整理和编辑。
知危:现在有一些新的基准测试在探索新的方式,以解决过去的方式带来的弊端。比如,一道题可能最初来自公开数据,但测试集中会刻意修改其中的数值,并且题目不对外公开,还有经常自动化更新等。您觉得这些做法能有效改善基准测试现状吗?
赵海:整体上,这类改变并不会带来太大影响。本质上来说,当前的大模型,尤其是推理型模型,在数学推理题方面已经做了大量优化。很多优化实际上涉及解题模式本身。以数学题为例,如果从中国考试体系的经验来看,出题虽然不能超纲,但老师和考官会想方设法出新题。不过模式是有限的,往往只是改一个数字而已。这样的改动其实很容易被大模型捕捉。换个数值作用不大,除非改动的是出题模式。现在我认为已经到了这个阶段。
知危:您认为 AI 大模型如果要进一步发展,在基准层面还能做哪些优化?
赵海:这个问题非常尖锐。我对这个领域一直持批评态度。虽然我们团队也确实做过一些数据集方面的工作,比如 CMMLU 等,但我认为这些本质上没有太多技术含量。我并不鼓励学生去做这类事情。
大模型时代的论文,整体上已经比较 “ 水 ” 了。现在大模型相关的研究里,有两类工作我觉得 “ 含水量 ” 比较高。第一类是做数据集,也就是所谓 Benchmark 的工作;第二类是写那些篇幅很长、引用很多文献的综述性文章。至于剩下的一些所谓技术性文章,大多只是渲染 “ 大模型能做这个 ” 或者 “ 大模型不能做这个 ”,缺乏真正突破。当然,这并不是说它们完全没有意义,只是我认为价值有限,作用不大。 当然新测试数据集发布时,我们可以用它在已有大模型之间做一些相对性的比较。但这种比较只是 “ 看看情况 ”,并不能真正反映综合能力。
因为现在的大模型不能简单看作是一个普通模型,更应该看作人的大脑 —— 当然实际距离人脑还差得远,否则就已经是 AGI 了。如果要谈人脑的评估,你不会只用一张试卷。
一个 Benchmark 就像是一张试卷,用它来衡量大模型的整体能力,本身就有局限性。更重要的是,大模型有点像 “ 过目不忘 ” 的人。因此用碎片的、静态的 Benchmark 究竟能评估什么,值得怀疑。我觉得目前这种评估方式,商业上的噱头可能更多一些。
总之就是:价值有限,但并不是完全没有意义。
知危:我们现在有一个观感是,国外各种新的 Benchmark 层出不穷,不管是语言、代码、自然科学等,甚至像 OpenAI 最近提出的评估模型经济价值的基准,而国内相关进展相对慢一些,对此您怎么看?
赵海:我觉得这件事其实没必要去争。前面说到,这件事并不是完全没有价值,但也并不是很有技术含量。很多 Benchmark 的来源,其实就是由大模型合成数据生成的。举个例子,我找一批题目,交给 OpenAI 最新的 GPT-5 或其他模型来生成答案,然后发布出来,这就成了一个新的 Benchmark。甚至其中不少都不是人工标注的,因为顶级大模型的效果已经足够好,本身就可以当作 “ 金标准 ”。
所以,这种工作的价值在哪里呢?无非就是让人看到,你和顶级大模型之间还有多大差距。如果说它有价值,也就仅限于此。
如果要用新数据做微调,从 ChatGPT 出现的第一天起,大家就在用 ChatGPT 回答的问题来标注对话数据。最初 ChatGPT 的数据确实是人工标注的,但后续把大语言模型变成对话式大语言模型时,所需的 SFT( 监督微调 )第一批数据,大概率就已经来自合成数据。这已经成为当前的主流模式。
基准测试或数据标注模式在特别细分、专业的数据领域可能有价值,尤其是一些几乎不可能合法流出的数据,比如医学相关的数据。如果通过人工标注来完成,这样的工作确实有意义。
但从长远来看,我认为 “ 大数据时代 ” 早就结束了。人类和互联网的数据总量就是这些,能用的搜索引擎公司基本都已经利用过。比如国内的百度、美国的谷歌,以及 OpenAI 可能用到微软 Bing 的数据,这些搜索引擎爬取的数据基本都被用了一遍,甚至还有更多的合成数据。
对于小规模、极其细分、专业领域的科学家标注,我认为无法改变这个大的趋势。未来这些工作很快都会被真正的 AGI 系统取代。为什么?因为真正的 AGI 系统无需依赖人工标注,能够自己亲手做实验、直接获取一手数据,再基于这些数据推出新的模型、新的方法和新技术。
知危:从您的个人感受来看,除了基准测试的数值本身不太可信之外,主流大模型的实际能力进步有多大?
赵海:从技术框架的角度来说,我认为主流大模型的进步并不大。现在的标准路径大致就是:大语言模型的涌现能力、对话的指令微调,再加上多模态。
关于能力的问题,大模型( 尤其是 GPT 系列 )的核心问题之一是 “ 幻觉 ”。
所谓幻觉,就是知识性错误:它的输出语言肯定是连贯流畅的,但事实判定可能不对,有时是 “ 瞎编 ” 的。从 ChatGPT 发布时间( 2022 年底 )到现在大约三年的时间,这方面其实进步还是蛮大的。OpenAI 声称幻觉减少很多,这一点我认为并没有夸大,确实有明显改善。
另外,大模型还有一项真正的能力,但一般大家不太谈:工程优化的强度。现在模型已经足够大,以至于掩盖了技术( 或者说工程上的优化 )在背后的作用。OpenAI 在这一点上比其他模型做得更好一些。我自己没有系统地用过最新版本,但根据学生的反馈以及我自己偶尔使用某些国产大模型的体验,可以明显感受到 “ 指令跟随 ” 这一点的差异。比如我要求模型执行某件事情时,有时它并没有按要求做,或者忽略了我的指令。这一点在最近使用某些国产大模型时尤其明显。
这背后原因不明,可能有些公司的 App 可能没有部署特别大号的模型,但也可能是技术不太过关。在商业化部署时,比如某家公司内部可能拥有 100B、200B、甚至 300B 参数规模的模型,但在实际部署到应用时,运行的可能只是 20B 或 30B 的模型。这主要是出于成本考虑。毕竟成千上万的用户在使用,而应用本身未必收费。如果直接部署 100B 规模的模型,电费和算力开销会非常惊人,公司根本无法承受。因此,这往往是商业策略问题。当然,也可能涉及技术性因素。比如 OpenAI,或许他们实际部署的并不是特别大的模型,而是通过模型压缩等优化手段,在保证效果的同时大幅降低了规模和成本。
除此之外,我认为其实没办法再列举更多了,核心的要求已经很明确,就是两点:指令遵循和减少幻觉。
其他的维度都没有这两点重要。比如,OpenAI 最近强调的长思维链模型( thinking ),通过超长自回归输出实现自我约束,确实让一些复杂数学题的表现更好。但这并不能从根本上说明问题。它只是利用自回归的特性强行把分数提高,而代价是输出过程变得极其冗长,效率大幅下降。
所以归根结底,指令遵循和幻觉控制是最基本、最核心的问题。但遗憾的是,在目前的框架下,这两个问题都还没有很好的解决方案。
知危:如何评估指令跟随能力是否足够好?是否需要非常复杂或动态的测试场景?
赵海:关于指令跟随的评估,并不一定需要特别复杂或动态的测试场景。更关键的是,对话数据要足够多,因为很难预测哪一条指令会触发问题。这种情况的比例其实很低,但用户一旦习惯了稳定的体验,就会对偶发的失误格外敏感。比如说,你习惯使用 OpenAI 的 工具,每次都能得到精准干脆的答案,那么当某个模型突然在 100 次交互中有一次没有很好地跟随指令时,用户就会觉得无法接受。虽然从统计上看,1% 的错误率并不算高,但在用户体验层面,感受完全不同。
所以,真正的技术进步体现在:即使模型规模不是特别大,但如果指令跟随和幻觉控制得很好,那才是真正有价值的提升。但是,用几千条、几万条的 Benchmark 数据集去评估,其实什么都评不出来。大家看到的成绩可能很亮眼,但并不代表真实能力。
甚至有些我刚刚提到过、在实际使用中指令跟随效果不佳的模型,在这些 Benchmark 上反而会得到虚高的成绩。
知危:关于工程上的优化,除了指令跟随能力,对工具的使用能力的提升,是不是也是很重要的一环?
赵海:今年被称为 “ Agent 元年 ”,但这个话题涉及到一个关键问题,它和我们之前讨论的指令跟随其实有一定相似之处。指令跟随的核心在于 SFT( 监督微调 )是否到位,而再往前追,则取决于预训练模型是否足够好。
工具调用不应该是一个难点。只要微调得好、数据标注充分,或者强化学习技巧足够成熟,大模型在单次工具调用上的能力是没有问题的。
真正的挑战在于:工具调用往往伴随着规划。举个例子,一个任务可能需要连续调用三个工具:第一个工具的输出作为输入传给第二个,再传给第三个,甚至可能进一步触发第四个工具。问题就在于,这个调用顺序、前后逻辑以及依赖关系的规划,本质上是一个数学上的规划问题。而规划的背后是数学和逻辑推理。大模型要在这种场景下表现好,就必须解决数学和逻辑的问题,而不仅仅是 “ 能不能调工具 ”。
关于目前主流的做法,其实过去的研究也不是没有 Agent 交互。只要模型足够强,Agent 之间的交互能力自然也会足够强,这是在历史条件下受到的技术限制。早期主要依赖 SFT( 监督微调 )和合成数据,而现在的趋势则转向强化学习。比如从 DeepSeek 开始,大家在尝试用强化学习替代传统方式。强化学习的优点在于,它在 Zero-shot 场景下可以省掉人工标注,相当于模型在生成合成数据的同时,边生成、边筛选、边进行自我微调。在工具调用方面,如果是通用模型,效果往往比较强大,覆盖面也广。如果是 “ Agent ”,涉及定制化的情况,就会更考验强化学习和微调的能力,而不再是预训练的优势。毕竟大规模预训练已经很难再推动。不过不幸的是,强化学习本身并不是一种稳定的训练算法,这也是目前最大的挑战和问题所在。
知危:前 OpenAI 研究员姚顺雨最近提到,当前 AI 在模型设计方法上的进步已经结束,下一步要集中在基准设计或任务设计。您对此怎么看?
赵海:这不叫 “ 结束了 ”,而是 “ 早就结束了 ”。实际上,从 2018 年开始,核心技术架构就已经停滞了。现在各家公司无非是在 Transformer 和 GPT 的参数调整、工程训练细节上做文章;即使是 OpenAI 也只是有一些工程优势,而非真正的革命性模型或新范式。你并没有不用 Transformer,也没有不用 GPT,仍然是这一套。
其实我并不认为我们现在探索的方向一定是最终胜利的。但可以 100% 肯定,目前主流方向不可能到达 AGI,至少无法达到我刚刚定义的那种标准。这并不是我一个人的观点,而是业内不少人的否定性共识。换句话说,我不能保证我一定赢,但可以肯定,这条现有的路一定会输。
知危:您认为应该怎么解决这些问题,或者如何才能实现 AGI?
赵海:我认为目前 GPT 这类大模型框架,乃至整个深度学习表征学习框架,都存在一个 “ AGI 瓶颈 ”。在这种框架下,不可能真正达到 AGI。
与人类相比,计算机和人的能力差异非常明显。比如人类的机械记忆其实非常差,让人背诵圆周率的前一百万位几乎不可能。但计算机却能在几秒钟内完成这一运算。我们不能因此说计算机的智能比人更高,因为这并不是评判智能的正确标准。
我们正在做的 “ 脑启发大语言模型 ” 工作,就是试图从这个角度去解决问题,寻找突破现有框架瓶颈的路径。 我们可以定义两种当前模式下几乎不可能获得的 “ AGI 瓶颈能力 ”。
第一种瓶颈是在输入端,模型应该天然支持多模态,而不需要依赖多模态数据的对齐。我把这一类称为“超模态学习”,并可以进一步扩展为 “ 超模态感知 ” 甚至是 “ 超模态创造 ”。
什么是 “ 超模态感知 ”?举个例子,人类既看不见也摸不到真空,但我们创造了 “ 真空 ” 的概念,并相信它确实存在,甚至在物理学中利用这个概念去推动新的发现。
同样的情况还有 “ 电磁场 ”,它不是人类感官可以直接获取的,但我们通过理论与实验验证确立了它的存在。这种能力超越了当前模型对 “ 多模态 ” 的理解。它不仅是把视觉、语言、声音等已知模态对齐,而是能够在现有感知、认知和知识( 例如数学理论、物理定律 )的基础上,创造出一种新的模态。这超出了目前所谓的 “ 世界模型 ” 的范畴。
无论是杨立昆提出的世界模型,还是李飞飞的相关研究,本质上仍是对已知世界的非语言模态进行更好的建模与刻画。这当然很有价值,但我所说的 “ 超模态 ” 能力,是这些世界模型无法达到的。第二种瓶颈与工具相关。这里说的不是工具调用,而是 “ 新工具的创造 ”。这是一个更高层次的能力。人类之所以能够成为智能生物,一个关键标志事件就是具备了创造并使用工具的能力。
很多人误以为 “ 使用工具 ” 才是人类与动物的分界线,但实际上并不是。真正的分界线在于 “ 创造工具 ”。哪怕只是把一块石头稍微磨平,然后再用它去敲碎另一件东西,这就已经是创造了新工具。目前的模型比如 GPT,还不能做到创造一个新的 Agent 并服务于我一开始定义的目标。
总之,在我所提出的两种 AGI 能力上,目前的主流模型是做不到的。现有的大模型,无论是纯语言模型,还是所谓的 “ 世界模型 ”( 即非语言大模型 ),基本上都还是在刻画已知的模态。语言这个模态很特殊,它是中心模态,也很有价值,但这仍然只是对已有模态进行对齐。数据可以人工标注或合成,通过这种方式,再加上常规的多模态输入、已有工具的调用与规划,如果不计成本,技术上也不是完全做不到,效果大体上可以接受。但一旦涉及到我之前所说的 “ 超模态学习与感知 ”,以及 “ 创造新工具、创造新 Agent,并把它们服务于宏观整体目标 ”,现有的框架在可见的条件下是做不到的。
知危:为了实现 “ 超模态感知 ” 和新工具创造,您的团队目前有哪些成果了呢?
赵海:我们现在的工作其实已经有了一些结果,这项研究会延续我们之前的 “ 脑启发大语言模型 briLLM ” 的成果和思路。它的核心架构叫作 SiFu,旨在取代目前的机器学习表征学习方法。通过这种方式,可以比较平滑、自然地解决我前面提到的问题,包括超模态感知与训练,突破多模态的瓶颈,以及创造新的概念和新的工具。
图源:https://arxiv.org/pdf/2503.11299
这其中的关键机制就是 “ 非表征学习 ”。它的核心在于不再使用当前机器学习的表征学习方式。简单来说,表征学习的做法是把输入信息转化为向量表示。比如词向量、句子向量,或者图像的向量编码等。以语言为例,无论是传统方法还是现在的深度学习,本质上都属于这种 “ 表征学习 ” 的思路。
举个例子,如果用三维向量表示类别:001 代表猫,010 代表狗。这就是典型的表征学习。不同的对象由不同的向量表示,但它们都处在同一个输入空间,只是数值不同而已。在输出端,如果模型要预测这是猫,就输出 001;如果是狗,就输出 010。这是一种 one-hot 表示。若不是 one-hot,而是更复杂的形式,比如 0.2、0.3 或 -7 来表示“猫”,这种方式就是 embedding。本质上,它依然属于表征学习。不同之处在于,embedding 的表征是通过机器学习模型自己不断更新、学到的,这就是深度学习。我们的思路是一开始就进行预定义,但不再依赖向量表示。举个例子,我在模型里直接设定若干模块:第一个模块代表猫,第二个模块代表狗,模块本身就直接对应语义对象。这种方式不再是表征学习,而是 “ 语义的直接映射 ”,语义对象和模型模块一一对应。
为什么要抛弃表征学习?因为从奥卡姆剃刀原则来看,表征学习并不是最简单的方案。比如你把 “ 猫 ” 表示为 010,把 “ 狗 ” 表示为 001,这样就需要一个编码器;即使是深度学习,也需要通过隐层去学习和映射。而语义直接映射则省去了这一过程,更加简洁。实际上,人脑也更接近于这种方式。
知危:为什么 “ 非表征学习 ” 在创造新工具和实现超模态学习方面会更有优势?
赵海:简单来说,如果继续采用表征学习,我们是用向量来表示语义对象;而在非表征学习里,我们用组件直接对应语义对象。
比如第一个组件代表猫,第二个组件代表狗。如果换成图片,依然可以保持这种映射关系。这样一来,模型就能在组件层面直接进行删减或替换,整个结构因此具备更高的可编辑性和灵活性。这种机制使得模型在扩展新概念、创造新工具,以及支持超模态感知和学习时,更加自然、高效。 在多模态的场景下,其实是否涉及语言并不重要。
对 “ 超模态 ” 的理解,可以这样来实现:如果现实世界中有具体的对象,比如猫和狗,它们分别对应模型中的第一个和第二个节点。那么,模型是否可以像人脑一样,自主定义一个新的组件?比如分配第三个节点,这个节点并不对应现实世界中的任何具体事物,而是代表“猫和狗的组合”,也就是“宠物”这样的概念。这就是“超模态”能力:创造新的概念。它可能在自然界中并不存在,但模型通过认知和抽象将其生成。从数学角度来看,这其实是非常自然、相对简单的过程。
这其实也是人脑的工作方式。比如,当你看到猫和狗时,大脑皮层中会分别激活不同的区域。但自然界中并不存在 “ 宠物 ” 这个概念。“ 宠物 ” 是人脑通过聚合 “ 猫 ” 和 “ 狗 ” 对应的区域,再在旁边分配一个新的大脑皮层区域,从而生成的一个新概念。
超模态是我们继 BriLLM 之后的下一阶段的研究方向,目前方案已经设计得差不多了,正在推进中。我并不是说全世界都走错了,现有的 GPT 这类模型依然有价值,成果也非常好。现在的模型帮助我们看到了 AGI 的 “ 山峰 ”,但这条路未必能登顶。就像高速公路不是通向山顶,而是从山的旁边绕过去一样,我们虽然到达了一个高处,也看见了山峰,但这条路径可能到此为止,无法直接通向山顶。
( 问答环节结束 )
回到对 AI 基准测试的探讨,从更宏观的角度,正如陶哲轩在使用 GPT-5 Pro 解决数学难题时所言,“ AI 在小尺度上很有用,中尺度上有些无益,大尺度上又有帮助。”
图源:https://mathstodon.xyz/@tao/115351400633010670
具体而言,陶哲轩曾指出,必须在多个尺度上衡量一个工具的有效性,比如这四个尺度:形式化证明中的任何单行、任何单个引理、任何定理的完整证明,以及整本教科书。
我们可以借鉴这句话,用不同于数学领域的视角来理解。
当前的基准测试大部分停留在小尺度上的单点确定性,只能按知识碎片的模板解决问题。
在中尺度,是极端追求全自动化、可扩展性和稳定性的工程化应用场景,目前大模型在这些场景也是类似陶哲轩所言,“有些无益”,AI社区也没有非常明确,应该在这些场景着重优化哪些能力维度。在本次探讨中反复提及的低幻觉、指令遵循、安全性、规划能力等,将会是未来AI发展的侧重点或共识,至于是通过基准测试还是其他方式来测量进展,还有待观望。
最后,在大尺度上,一般是在顶尖专家最高决策者监督下,大模型发散思维并协同人类对问题进行深度研究,这些问题一般是超越人类当前知识和经验范畴的。人类无须纠结最后结果是否正确,只需取其中片段的思路或技术点,便能获得研究或决策进展,或继续推动大模型深入探索。这种级别的问题不具备普适性,没有也不需要基准测试来检测 AI 在这方面的潜力,而每一个问题都会对 AGI 的探索带来一丝启发。
更新内容
一、修复bug,修改自动播放;优化产品用户体验。
二、 1.修复已知Bug。2.新服务。
三、修复已知bug;优化用户体验
四、1,交互全面优化,用户操作更加便捷高效;2,主题色更新,界面风格更加协调;3,增加卡片类个人数据
五、-千万商品随意挑选,大图展现商品细节-订单和物流查询实时同步-支持团购和名品特卖,更有手机专享等你抢-支付宝和银联多种支付方式,轻松下单,快捷支付-新浪微博,支付宝,QQ登录,不用注册也能购物-支持商品收藏,随时查询喜爱的商品和历史购物清单。
六、1.bug修复,提升用户体验;2.优化加载,体验更流程;3.提升安卓系统兼容性
七、1、修复部分机型bug;2、提高游戏流畅度;
厂商其他下载
安卓应用 安卓手游 苹果应用 苹果手游 电脑 更多+
-
 2025LPL全明星正赛选手阵容
2025LPL全明星正赛选手阵容
-
 陆柯燃谈30岁
陆柯燃谈30岁
-
 南昌双子塔下的银杏太出片了
南昌双子塔下的银杏太出片了
-
 小米辣涨到28元1斤 市民:顶两斤肉
小米辣涨到28元1斤 市民:顶两斤肉
-
 河北厂二代夫妻借直播救工厂
河北厂二代夫妻借直播救工厂
-
 得闲谨制预售总票房破亿
得闲谨制预售总票房破亿
-
 小小文淇 签约公司是终身大事
小小文淇 签约公司是终身大事
-
 小狗也懂事不过三的道理
小狗也懂事不过三的道理
-
 大生意人
大生意人
-
 教资面试穿搭已经准备好了
教资面试穿搭已经准备好了
-
 金建希出庭受审被搀扶着走入法庭
金建希出庭受审被搀扶着走入法庭
-
 郭正亮:若日本军事介入台海视同侵略
郭正亮:若日本军事介入台海视同侵略
-
 易烊千玺因身体原因终止原定进组安排
易烊千玺因身体原因终止原定进组安排
-
 万妮达演唱会偶遇李嘉格和新男友
万妮达演唱会偶遇李嘉格和新男友
-
 李晟说江一燕不拍戏浪费了
李晟说江一燕不拍戏浪费了
-
 预制大学转场风刮到了baby界
预制大学转场风刮到了baby界
-
 爱马仕继承人起诉LVMH集团
爱马仕继承人起诉LVMH集团
-
 荒野求生文车车退赛
荒野求生文车车退赛
-
 支持这个陈都灵兔子警官
支持这个陈都灵兔子警官
-
 普京下车登机安保团队迅速列队警戒
普京下车登机安保团队迅速列队警戒
相关版本
- 中文名:建议你不要再相信AI基准测试,排行榜已经没啥公信力了
- 包名:com.ejiaqrp.dtgen
- MD5:P7ENQIWOC1RTO1T6EP
查看所有 0条评论>网友评论
- 相关游戏
-
 大先生教父的含金量还在上升
大先生教父的含金量还在上升
 香奈儿大秀
香奈儿大秀
 测测你的动物城角色
测测你的动物城角色
 刘诗诗配音幕后花絮
刘诗诗配音幕后花絮
 云南bigbang发布原创歌曲
云南bigbang发布原创歌曲
 玄界之门石牧遭踢馆
玄界之门石牧遭踢馆
 弟弟给住校的姐姐带东西件件都是爱
弟弟给住校的姐姐带东西件件都是爱
 东北火炉南方取暖记
东北火炉南方取暖记
 2025年十大流行语
2025年十大流行语
 实名羡慕这些街拍摄影师
实名羡慕这些街拍摄影师
 中俄进行战略对表 高市还敢搞事吗
中俄进行战略对表 高市还敢搞事吗
 镖人第二季过审
镖人第二季过审
 奥司他韦已出现耐药情况
奥司他韦已出现耐药情况
 高市早苗终于不嘴硬了
高市早苗终于不嘴硬了
 台湾小学校歌歌词做堂堂正正中国人
台湾小学校歌歌词做堂堂正正中国人
 余茵马小宇抽象到一起了
余茵马小宇抽象到一起了
 知识进不去的地方 甲流也进不去
知识进不去的地方 甲流也进不去
 全网首个老实人男团来了
全网首个老实人男团来了
 镖人第二季过审
镖人第二季过审
 张俪演技
张俪演技
 安静公主亮司合拍氛围感拉满
安静公主亮司合拍氛围感拉满
 粉丝再多都不可踩踏底线
粉丝再多都不可踩踏底线
 正片观众 切片观众
正片观众 切片观众
 王楚钦捂嘴vs梁靖崑捂嘴
王楚钦捂嘴vs梁靖崑捂嘴
 普京下车登机安保团队迅速列队警戒
普京下车登机安保团队迅速列队警戒
 无库版勇三疯上演
无库版勇三疯上演
 王一博沉迷拍照
王一博沉迷拍照
 蝴蝶忍cos
蝴蝶忍cos
 亦舞之城前任结婚新娘不是我
亦舞之城前任结婚新娘不是我
 荒野求生林北退赛 获得2000元奖金
荒野求生林北退赛 获得2000元奖金
 朱雀三号首飞
朱雀三号首飞
 吴艳妮在姐姐婚礼上致辞数次落泪
吴艳妮在姐姐婚礼上致辞数次落泪
 枭起青壤 全员科班
枭起青壤 全员科班
 安万和粉丝双向奔赴
安万和粉丝双向奔赴
 亦舞之城前任结婚新娘不是我
亦舞之城前任结婚新娘不是我
 李在明希望能够尽早访华
李在明希望能够尽早访华
 侯鸿亮啥也不说了给大家鞠一躬
侯鸿亮啥也不说了给大家鞠一躬
 安静公主亮司合拍氛围感拉满
安静公主亮司合拍氛围感拉满
 副部叶红专被查
副部叶红专被查
 李嘉格和男友相差9岁
李嘉格和男友相差9岁
- 更多>心动网络手游
-
 遇到难回答的问题就不说话了
遇到难回答的问题就不说话了
 米卡出道4年上了48本封面
米卡出道4年上了48本封面
 倡议村民自觉停用土炕 不能一封了之
倡议村民自觉停用土炕 不能一封了之
 刘诗诗配音幕后花絮
刘诗诗配音幕后花絮
 朱雀三号回收失败原因正在分析
朱雀三号回收失败原因正在分析
 阎王爷成“解压神” 横店NPC们爆火
阎王爷成“解压神” 横店NPC们爆火
 央视起底骗保黑灰产业链
央视起底骗保黑灰产业链
 阿米嘎蒂朵猫是什么梗
阿米嘎蒂朵猫是什么梗
 吉林长岭通缉34岁姚某
吉林长岭通缉34岁姚某
 崔立于solo
崔立于solo
 不死鸟给我擦皮鞋
不死鸟给我擦皮鞋
 四川绵阳发生山体火灾系谣言
四川绵阳发生山体火灾系谣言
 邓为的澳门地广已上线
邓为的澳门地广已上线
 很认真的记住了对方的生日
很认真的记住了对方的生日
 李嘉格和男友相差9岁
李嘉格和男友相差9岁
 一节课讲清楚电视机成像原理
一节课讲清楚电视机成像原理
 无名之辈意义非凡
无名之辈意义非凡
 陈赫客串陈小春演唱会vlog来了
陈赫客串陈小春演唱会vlog来了
 终于轮到我拍猗窝座经典招式了
终于轮到我拍猗窝座经典招式了
 李嘉格捂嘴偷笑
李嘉格捂嘴偷笑
 李嘉格回应恋情
李嘉格回应恋情
 李嘉格捂嘴偷笑
李嘉格捂嘴偷笑
 荒野求生林北退赛
荒野求生林北退赛
 2025KPL年总纪录片决赛篇
2025KPL年总纪录片决赛篇
 挑战分饰疯狂动物城2多个角色
挑战分饰疯狂动物城2多个角色
 给对方花钱感情浓度会迅速降低
给对方花钱感情浓度会迅速降低
 带你一口气看完电影山怪巨魔2
带你一口气看完电影山怪巨魔2
 做了心心念念的电饭煲蛋糕
做了心心念念的电饭煲蛋糕
 女儿偷偷回国发现爸爸开出租
女儿偷偷回国发现爸爸开出租
 李昀锐周末画报封面
李昀锐周末画报封面
 万达债务“解套”了吗
万达债务“解套”了吗
 王楚钦说自己在混双比以前调节更好
古平原救慈禧
王楚钦说自己在混双比以前调节更好
古平原救慈禧
 河北厂二代夫妻借直播救工厂
河北厂二代夫妻借直播救工厂
 胡先煦杀进内娱hot nerd赛道
胡先煦杀进内娱hot nerd赛道
 阿爆亲了方头明
阿爆亲了方头明
 朱雀三号重复使用火箭发射入轨
朱雀三号重复使用火箭发射入轨
 四川绵阳发生山体火灾系谣言
四川绵阳发生山体火灾系谣言
 四川绵阳发生山体火灾系谣言
四川绵阳发生山体火灾系谣言
 侯鸿亮发博
侯鸿亮发博
- 更多>mod游戏
-
 忙碌20集1觉回到宁古塔
忙碌20集1觉回到宁古塔
 国台办驳斥王世坚言论
国台办驳斥王世坚言论
 李昀锐西装版抖肩舞
李昀锐西装版抖肩舞
 帅哥版宝伯特盖瑞
帅哥版宝伯特盖瑞
 这就是刻在骨子里的修养
这就是刻在骨子里的修养
 高市早苗称日本政府对台立场没改变
高市早苗称日本政府对台立场没改变
 越南前空姐伙同男友组织200人卖淫
越南前空姐伙同男友组织200人卖淫
 陶喆 这很难吗
陶喆 这很难吗
 曝王梓莼高中请假条
曝王梓莼高中请假条
 入殓师称同事服务猝死老人被托梦质问
入殓师称同事服务猝死老人被托梦质问
 蒲言延王子腾告白夜BE
蒲言延王子腾告白夜BE
 业内曝中国文娱势力版图
业内曝中国文娱势力版图
 胡先煦杀进内娱hot nerd赛道
胡先煦杀进内娱hot nerd赛道
 追星能不能现在也按这样来
追星能不能现在也按这样来
 汪东城 接委托
汪东城 接委托
 新国标电动车坐垫设计
新国标电动车坐垫设计
 被英文提问攻击的陈哲远
被英文提问攻击的陈哲远
 洛克王国世界定档
洛克王国世界定档
 荒野求生林北退赛
荒野求生林北退赛
 朱雀三号发射为何经历多次延期
朱雀三号发射为何经历多次延期
 夫妻买别墅7间屋子有6间甲醛超标
夫妻买别墅7间屋子有6间甲醛超标
 梁洁也被班味腌入味了
梁洁也被班味腌入味了
 谍报上不封顶
谍报上不封顶
 化那么漂亮跳得跟屎一样有用吗
化那么漂亮跳得跟屎一样有用吗
 包包的恋综日记
包包的恋综日记
 快船为何选择与保罗分手
快船为何选择与保罗分手
 帅哥版宝伯特盖瑞
帅哥版宝伯特盖瑞
 人造太阳点亮万亿赛道
人造太阳点亮万亿赛道
 今年流感猛是因为核心毒株变了
今年流感猛是因为核心毒株变了
 养异宠要做好心理准备
养异宠要做好心理准备
 育儿补贴申领截止到12月31日
锐评BLG 2026年新阵容
育儿补贴申领截止到12月31日
锐评BLG 2026年新阵容
 肖战角色包场得闲谨制
肖战角色包场得闲谨制
 辛芷蕾看秀从从容容游刃有余
辛芷蕾看秀从从容容游刃有余
 电影得闲谨制五代人中间少了两代
电影得闲谨制五代人中间少了两代
 本周末F1收官战前瞻
本周末F1收官战前瞻
 王楚钦说自己在混双比以前调节更好
王楚钦说自己在混双比以前调节更好
 挑战分饰疯狂动物城2多个角色
挑战分饰疯狂动物城2多个角色
 奥迪Q5L裸车价降至23万多
奥迪Q5L裸车价降至23万多
 欧阳娜娜巴厘岛vlog
欧阳娜娜巴厘岛vlog
- 更多>像素rpg游戏
-
 Lisa羊毛卷造型亮相LV活动
Lisa羊毛卷造型亮相LV活动
 余茵马小宇抽象到一起了
余茵马小宇抽象到一起了
 即刻上场办公室恋情好嗑
即刻上场办公室恋情好嗑
 钟汉良一出现就像偶像剧
钟汉良一出现就像偶像剧
 谁说黑色显瘦的
谁说黑色显瘦的
 抖音音乐年终狂想
抖音音乐年终狂想
 日本自卫队被曝正在向西南转移
日本自卫队被曝正在向西南转移
 锐评BLG 2026年新阵容
锐评BLG 2026年新阵容
 食物可能含黄曲霉素的表现
食物可能含黄曲霉素的表现
 偏爱之恋张雪菲马浩翔官宣
偏爱之恋张雪菲马浩翔官宣
 中国机器人哨兵站岗中印边境
中国机器人哨兵站岗中印边境
 聂九罗炎拓心动环环相扣
聂九罗炎拓心动环环相扣
 支持这个陈都灵兔子警官
支持这个陈都灵兔子警官
 一条秋裤可能不够了
一条秋裤可能不够了
 2025内娱双人舞cha
2025内娱双人舞cha
 不能错过的双12必买清单
不能错过的双12必买清单
 我国履行碳减排承诺取得实际成效
我国履行碳减排承诺取得实际成效
 被人卖了还美滋滋的帮别人数钱
被人卖了还美滋滋的帮别人数钱
 外媒关注中国民企廉价高超音速导弹
外媒关注中国民企廉价高超音速导弹
 林诗栋说能上场很开心
林诗栋说能上场很开心
 日本自卫队被曝正在向西南转移
日本自卫队被曝正在向西南转移
 易烊千玺曾为拍好小小的我关节变形
易烊千玺曾为拍好小小的我关节变形
 明宰铉 排骨汤
明宰铉 排骨汤
 时代峰峻说朱志鑫单飞纯属造谣
时代峰峻说朱志鑫单飞纯属造谣
 女子用绳子挡电梯门致电梯突停
女子用绳子挡电梯门致电梯突停
 易烊千玺粉丝质疑经纪人
易烊千玺粉丝质疑经纪人
 想用陈立农同款BGM
想用陈立农同款BGM
 真让健身小胖拿冠军了
真让健身小胖拿冠军了
 水果姐特鲁多牵手出行
水果姐特鲁多牵手出行
 烟台的雪下到模糊了
烟台的雪下到模糊了
 李纯超绝不经意展示婚戒
李纯超绝不经意展示婚戒
 传说中的金刚芭比
传说中的金刚芭比
 沈腾范丞丞拳击全是试探
沈腾范丞丞拳击全是试探
 四川绵阳发生山体火灾系谣言
四川绵阳发生山体火灾系谣言
 易烊千玺曾为拍好小小的我关节变形
易烊千玺曾为拍好小小的我关节变形
 郑秀晶拍继承者们被摔的包是姐姐的
郑秀晶拍继承者们被摔的包是姐姐的
 香港火灾已致159人遇难
香港火灾已致159人遇难
 谍报上不封顶
谍报上不封顶
 也许你不会懂
也许你不会懂
 李昀锐路透造型被识别成AI了
李昀锐路透造型被识别成AI了
-
2025-12-04
1

-
2025-12-04
2

-
2025-12-04
3

-
2025-12-04
4

-
2025-12-04
5

-
2025-12-04
6

-
2025-12-04
7

-
2025-12-04
8

-
2025-12-04
9

-
2025-12-04
10

-
2025-12-04
11
-
2025-12-04
12

-
2025-12-04
13

-
2025-12-04
14

-
2025-12-04
15

-
2025-12-04
16

-
2025-12-04
17

-
2025-12-04
18

-
2025-12-04
19

-
2025-12-04
20

-
2025-12-04
21

-
2025-12-04
22

-
2025-12-04
23

-
2025-12-04
24

-
2025-12-04
25

-
2025-12-04
26

-
2025-12-04
27

-
2025-12-04
28

-
2025-12-04
29

-
2025-12-04
30

-
2025-12-04
31

-
2025-12-04
32

-
2025-12-04
33

-
2025-12-04
34

-
2025-12-04
35

-
2025-12-04
36

-
2025-12-04
37

-
2025-12-04
38

-
2025-12-04
39

-
2025-12-04
40

-
2025-12-04
41

-
2025-12-04
42

-
2025-12-04
43

-
2025-12-04
44

-
2025-12-04
45

-
2025-12-04
46

-
2025-12-04
47

-
2025-12-04
48

-
2025-12-04
49

-
2025-12-04
50

-
2025-12-04
51

-
2025-12-04
52

-
2025-12-04
53

-
2025-12-04
54

-
2025-12-04
55

-
2025-12-04
56

-
2025-12-04
57

-
2025-12-04
58

-
2025-12-04
59

-
2025-12-04
60

-
2025-12-04
61

-
2025-12-04
62

-
2025-12-04
63

-
2025-12-04
64

-
2025-12-04
65

-
2025-12-04
66

-
2025-12-04
67

-
2025-12-04
68

-
2025-12-04
69

-
2025-12-04
70

-
2025-12-04
71

-
2025-12-04
72

-
2025-12-04
73

-
2025-12-04
74

-
2025-12-04
75

-
2025-12-04
76

-
2025-12-04
77

-
2025-12-04
78
-
2025-12-04
79

-
2025-12-04
80

-
2025-12-04
81

-
2025-12-04
82

-
2025-12-04
83

-
2025-12-04
84

-
2025-12-04
85

-
2025-12-04
86

-
2025-12-04
87
-
2025-12-04
88

-
2025-12-04
89

-
2025-12-04
90

-
2025-12-04
91

-
2025-12-04
92
-
2025-12-04
93

-
2025-12-04
94

-
2025-12-04
95

-
2025-12-04
96

-
2025-12-04
97

-
2025-12-04
98

-
2025-12-04
99

-
2025-12-04
100

-
2025-12-04
101
-
2025-12-04
102

-
2025-12-04
103

-
2025-12-04
104

-
2025-12-04
105

-
2025-12-04
106

-
2025-12-04
107

-
2025-12-04
108
-
2025-12-04
109
-
2025-12-04
110

-
2025-12-04
111

-
2025-12-04
112

-
2025-12-04
113

-
2025-12-04
114

-
2025-12-04
115

-
2025-12-04
116
-
2025-12-04
117

-
2025-12-04
118

-
2025-12-04
119

-
2025-12-04
120

-
2025-12-04
121

-
2025-12-04
122

-
2025-12-04
123

-
2025-12-04
124

-
2025-12-04
125

-
2025-12-04
126

-
2025-12-04
127

-
2025-12-04
128

-
2025-12-04
129

-
2025-12-04
130

-
2025-12-04
131

-
2025-12-04
132

-
2025-12-04
133

-
2025-12-04
134
-
2025-12-04
135
-
2025-12-04
136

-
2025-12-04
137

-
2025-12-04
138

-
2025-12-04
139

-
2025-12-04
140

-
2025-12-04
141

-
2025-12-04
142

-
2025-12-04
143

-
2025-12-04
144

-
2025-12-04
145

-
2025-12-04
146

-
2025-12-04
147

-
2025-12-04
148

-
2025-12-04
149

-
2025-12-04
150

-
2025-12-04
151

-
2025-12-04
152

-
2025-12-04
153

-
2025-12-04
154

-
2025-12-04
155

-
2025-12-04
156

-
2025-12-04
157

-
2025-12-04
158

-
2025-12-04
159

-
2025-12-04
160

-
2025-12-04
161

-
2025-12-04
162

-
2025-12-04
163

-
2025-12-04
164

-
2025-12-04
165

-
2025-12-04
166

-
2025-12-04
167

-
2025-12-04
168

-
2025-12-04
169

-
2025-12-04
170

-
2025-12-04
171

-
2025-12-04
172

-
2025-12-04
173

-
2025-12-04
174

-
2025-12-04
175

-
2025-12-04
176

-
2025-12-04
177

-
2025-12-04
178

-
2025-12-04
179

-
2025-12-04
180

-
2025-12-04
181

-
2025-12-04
182

-
2025-12-04
183

-
2025-12-04
184

-
2025-12-04
185

-
2025-12-04
186
-
2025-12-04
187

-
2025-12-04
188

-
2025-12-04
189

-
2025-12-04
190

-
2025-12-04
191

-
2025-12-04
192

-
2025-12-04
193

-
2025-12-04
194

-
2025-12-04
195

-
2025-12-04
196

-
2025-12-04
197

-
2025-12-04
198

-
2025-12-04
199

-
2025-12-04
200

-
2025-12-04
201

-
2025-12-04
202

-
2025-12-04
203

-
2025-12-04
204
-
2025-12-04
205

-
2025-12-04
206

-
2025-12-04
207
-
2025-12-04
208

-
2025-12-04
209

-
2025-12-04
210

-
2025-12-04
211

-
2025-12-04
212

-
2025-12-04
213

-
2025-12-04
214

-
2025-12-04
215

-
2025-12-04
216

-
2025-12-04
217

-
2025-12-04
218

-
2025-12-04
219

-
2025-12-04
220

-
2025-12-04
221

-
2025-12-04
222

-
2025-12-04
223

-
2025-12-04
224

-
2025-12-04
225

-
2025-12-04
226

-
2025-12-04
227

-
2025-12-04
228
-
2025-12-04
229
-
2025-12-04
230

-
2025-12-04
231
-
2025-12-04
232

-
2025-12-04
233

-
2025-12-04
234

-
2025-12-04
235
-
2025-12-04
236

-
2025-12-04
237

-
2025-12-04
238

-
2025-12-04
239
-
2025-12-04
240

-
2025-12-04
241
-
2025-12-04
242
-
2025-12-04
243

-
2025-12-04
244

-
2025-12-04
245

-
2025-12-04
246

-
2025-12-04
247

-
2025-12-04
248

-
2025-12-04
249

-
2025-12-04
250

-
2025-12-04
251

-
2025-12-04
252

-
2025-12-04
253
-
2025-12-04
254

-
2025-12-04
255

-
2025-12-04
256

-
2025-12-04
257

-
2025-12-04
258
-
2025-12-04
259

-
2025-12-04
260

-
2025-12-04
261

-
2025-12-04
262

-
2025-12-04
263

-
2025-12-04
264

-
2025-12-04
265

-
2025-12-04
266

-
2025-12-04
267

-
2025-12-04
268

-
2025-12-04
269

-
2025-12-04
270

-
2025-12-04
271

-
2025-12-04
272

-
2025-12-04
273

-
2025-12-04
274

-
2025-12-04
275

-
2025-12-04
276

-
2025-12-04
277

-
2025-12-04
278

-
2025-12-04
279

-
2025-12-04
280

-
2025-12-04
281

-
2025-12-04
282

-
2025-12-04
283

-
2025-12-04
284
-
2025-12-04
285

-
2025-12-04
286

-
2025-12-04
287

-
2025-12-04
288
-
2025-12-04
289

-
2025-12-04
290

-
2025-12-04
291
-
2025-12-04
292

-
2025-12-04
293

-
2025-12-04
294

-
2025-12-04
295

-
2025-12-04
296

-
2025-12-04
297

-
2025-12-04
298

-
2025-12-04
299

-
2025-12-04
300

-
2025-12-04
301

-
2025-12-04
302

-
2025-12-04
303

-
2025-12-04
304

-
2025-12-04
305

-
2025-12-04
306

-
2025-12-04
307

-
2025-12-04
308

-
2025-12-04
309

-
2025-12-04
310

-
2025-12-04
311

-
2025-12-04
312

-
2025-12-04
313

-
2025-12-04
314

-
2025-12-04
315

-
2025-12-04
316

-
2025-12-04
317

-
2025-12-04
318

-
2025-12-04
319

-
2025-12-04
320

-
2025-12-04
321

-
2025-12-04
322
-
2025-12-04
323

-
2025-12-04
324

-
2025-12-04
325

-
2025-12-04
326

-
2025-12-04
327

-
2025-12-04
328

-
2025-12-04
329

-
2025-12-04
330

-
2025-12-04
331

-
2025-12-04
332

-
2025-12-04
333

-
2025-12-04
334

-
2025-12-04
335

-
2025-12-04
336

-
2025-12-04
337

-
2025-12-04
338
-
2025-12-04
339

-
2025-12-04
340

-
2025-12-04
341

-
2025-12-04
342

-
2025-12-04
343

-
2025-12-04
344

-
2025-12-04
345

-
2025-12-04
346

-
2025-12-04
347

-
2025-12-04
348

-
2025-12-04
349

-
2025-12-04
350
-
2025-12-04
351

-
2025-12-04
352

-
2025-12-04
353

-
2025-12-04
354

-
2025-12-04
355

-
2025-12-04
356

-
2025-12-04
357

-
2025-12-04
358

-
2025-12-04
359

-
2025-12-04
360

-
2025-12-04
361

-
2025-12-04
362

-
2025-12-04
363

-
2025-12-04
364

-
2025-12-04
365

-
2025-12-04
366

-
2025-12-04
367

-
2025-12-04
368

-
2025-12-04
369

-
2025-12-04
370

-
2025-12-04
371

-
2025-12-04
372

-
2025-12-04
373

-
2025-12-04
374

-
2025-12-04
375

-
2025-12-04
376

-
2025-12-04
377

-
2025-12-04
378

-
2025-12-04
379

-
2025-12-04
380

-
2025-12-04
381

-
2025-12-04
382

-
2025-12-04
383

-
2025-12-04
384

-
2025-12-04
385

-
2025-12-04
386

-
2025-12-04
387

-
2025-12-04
388

-
2025-12-04
389

-
2025-12-04
390

-
2025-12-04
391

-
2025-12-04
392

-
2025-12-04
393

-
2025-12-04
394

-
2025-12-04
395

-
2025-12-04
396

-
2025-12-04
397

-
2025-12-04
398

-
2025-12-04
399

-
2025-12-04
400

-
2025-12-04
1

-
2025-12-04
2

-
2025-12-04
3

-
2025-12-04
4

-
2025-12-04
5

-
2025-12-04
6

-
2025-12-04
7

-
2025-12-04
8

-
2025-12-04
9

-
2025-12-04
10

-
2025-12-04
11
-
2025-12-04
12

-
2025-12-04
13

-
2025-12-04
14

-
2025-12-04
15

-
2025-12-04
16

-
2025-12-04
17

-
2025-12-04
18

-
2025-12-04
19

-
2025-12-04
20

-
2025-12-04
21

-
2025-12-04
22

-
2025-12-04
23

-
2025-12-04
24

-
2025-12-04
25

-
2025-12-04
26
-
2025-12-04
27

-
2025-12-04
28

-
2025-12-04
29

-
2025-12-04
30

-
2025-12-04
31

-
2025-12-04
32

-
2025-12-04
33

-
2025-12-04
34

-
2025-12-04
35

-
2025-12-04
36

-
2025-12-04
37

-
2025-12-04
38

-
2025-12-04
39

-
2025-12-04
40

-
2025-12-04
41

-
2025-12-04
42

-
2025-12-04
43

-
2025-12-04
44

-
2025-12-04
45

-
2025-12-04
46

-
2025-12-04
47

-
2025-12-04
48

-
2025-12-04
49

-
2025-12-04
50

-
2025-12-04
51

-
2025-12-04
52

-
2025-12-04
53

-
2025-12-04
54

-
2025-12-04
55

-
2025-12-04
56

-
2025-12-04
57

-
2025-12-04
58
-
2025-12-04
59

-
2025-12-04
60

-
2025-12-04
61

-
2025-12-04
62

-
2025-12-04
63

-
2025-12-04
64

-
2025-12-04
65

-
2025-12-04
66

-
2025-12-04
67

-
2025-12-04
68

-
2025-12-04
69

-
2025-12-04
70

-
2025-12-04
71

-
2025-12-04
72
-
2025-12-04
73

-
2025-12-04
74

-
2025-12-04
75

-
2025-12-04
76

-
2025-12-04
77

-
2025-12-04
78

-
2025-12-04
79

-
2025-12-04
80

-
2025-12-04
81

-
2025-12-04
82

-
2025-12-04
83

-
2025-12-04
84

-
2025-12-04
85

-
2025-12-04
86

-
2025-12-04
87

-
2025-12-04
88
-
2025-12-04
89

-
2025-12-04
90

-
2025-12-04
91
-
2025-12-04
92

-
2025-12-04
93

-
2025-12-04
94

-
2025-12-04
95

-
2025-12-04
96

-
2025-12-04
97

-
2025-12-04
98

-
2025-12-04
99

-
2025-12-04
100

